How outdated information hides in LLM token generation probabilities and creates logical inconsistencies

The internet usually has the correct answer somewhere, but it’s also full of conflicting and outdated information. How do large language models (LLMs) such as ChatGPT, trained on internet scale data, handle cases where there’s conflicting or outdated information? (Hint: it’s not always the most recent answer as of the knowledge cutoff date; think about what LLMs are trained to do)
In this article, I’m going to briefly cover some of the basics so we can think this through from first principles and then have a peek at the token generation probabilities, working our way from GPT-2 through to the most recent 4o series of models. We’ll then explore the very strange behaviour that arises when an LLM has learned both the correct and outdated information, believing both to be simultaneously true yet also contradictory. I’m going to use the height of a mountain as a running example of something that should be consistent but isn’t. Although if you don’t care as much as me about the height of some mountain you’ve never heard of (shame on you), keep in mind these principles also apply to things like the recommended dosage of medications, or if you use AI code assistants, things like which library function parameters are required/deprecated and network timeout behaviour for different platforms.
The knowledge cutoff isn’t as simple as it seems
You may have seen ChatGPT use a phrase such as “as of my knowledge cutoff” (try searching that phrase on Google Scholar). However, knowledge cutoffs are not as simple as they seem, because crawls of the internet (or whatever other sources LLM creators use, OpenAI doesn’t say exactly what they put in) don’t just contain the most recent information as of that date, there’s also a lot of old or duplicated information from the past.
Unlike humans who construct their internal knowledge of the world over time, deliberating over which knowledge is correct and which should be discarded as old or obsolete, LLMs have no such concept.
A model is only as good as its data
In my last post, correcting outdated facts in Wikidata, I investigated a case where some websites claimed Mount Bartle Frere (the highest mountain in Queensland, Australia) was 1,622 metres above sea level, while others claimed it was 1,611 metres. After spending days attempting to trace it back to the underlying source, I found an official survey record from 2016. It used GPS-based surveying equipment to accurately measure the height with centimetre-level accuracy, which showed the mountain was 1,611 metres above sea level, 11 metres less than previously thought. But some government websites continue to claim that Mount Bartle Frere is 1,622 metres and is also what appears at the top of Google if you search for the elevation of Mount Bartle Frere, despite this figure having been outdated for over 8 years now.
So, which answer will an LLM give? Let’s think about what an (autoregressive) LLM really is. It’s a neural network (usually a transformer architecture nowadays) that’s been trained to predict what word comes next. Or if you want to be precise, the next token (part-word). And then we just run it in a loop to generate the full answer, token by token.
Smaller models, like GPT-2, learn to generate grammatically correct but often nonsensical information. For example, when prompted with “The height of Mount Bartle Frere, in metres, is” GPT-2 might follow this with something like “about 1,000 metres”.
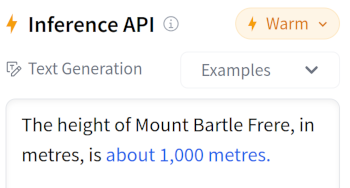
GPT-2 XL (interactive demo on Hugging Face)
While GPT-2 is terrible by today’s standards, the idea is that with a larger model and more data, LLMs will learn to generate factually accurate responses, not just grammatically correct responses. Let’s compare this to GPT-3. The OpenAI completion playground (soon to be removed) allows us to visualise the probabilities of generating the next token. In this case “1” and “,” are generated as individual tokens, but the interesting part is which token is predicted to come next:
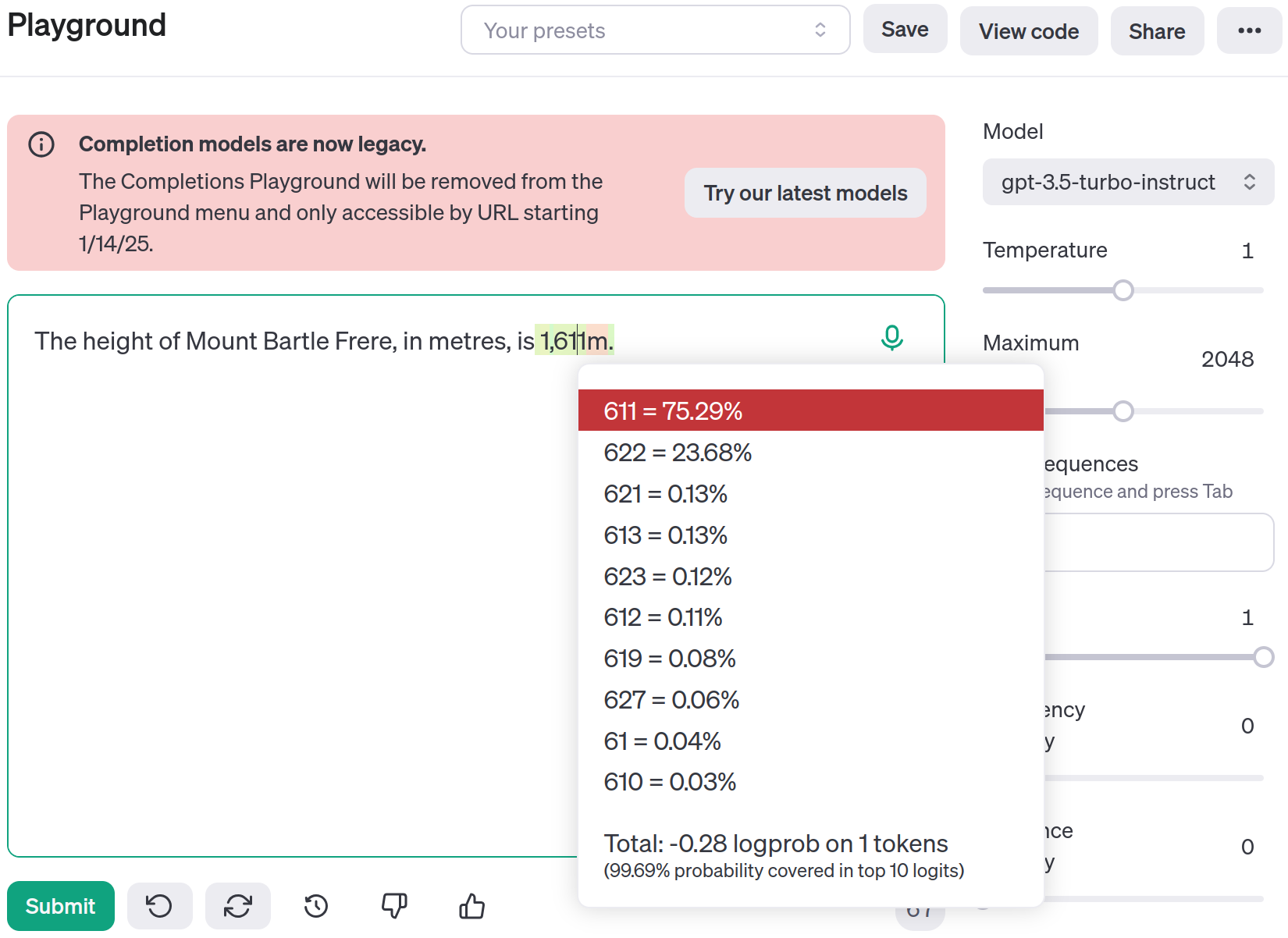
https://platform.openai.com/playground/complete?model=gpt-3.5-turbo-instruct
As we can see from the underlying probabilities, “611” is most likely to follow at 75.29% probability, but “622” is also a likely candidate at 23.68% probability. It’s actually learned both! That shouldn’t come as a surprise when we think about what an LLM fundamentally is and how they are trained. LLMs learn a probability distribution over the set of tokens. So if some of the training data has 1,611 metres and other training data has 1,622 metres, then it needs to learn both are possible and with what probability in the given context.
On a technical note, when it comes to actually generating text, these don’t need to match the probabilities learned from the training data. This is controlled by the “temperature” parameter, for example, a temperature of zero will pick the most likely token to come next rather than at random according to the probabilities in the training data. If you turn the temperature down to 0, in this case you will always get the correct answer of 1,611 metres - though as we will see later, slight variations in the prompt can tip the delicate balance of probabilities resulting in always getting the wrong answer instead. I’m also glossing over the details of instruction tuning in which the model is fine-tuned to answer questions rather than just complete sentences.
GPT-3 is old, so let’s skip ahead to GPT-4o:
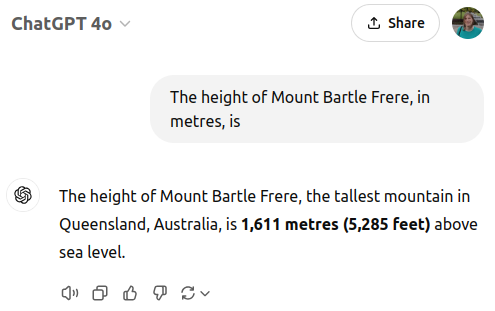
https://chatgpt.com/share/6774da47-0d1c-800a-a162-6f715213fce4
You may have noticed that I didn’t visualise the probabilities this time. There’s a reason for that, OpenAI doesn’t provide an easy way to view them. However, it is possible to get logits (log probabilities, which we can convert to percentages) through the API, and I’ve included my code to do this in this Github Gist.
Using the API when we can examine the probability distribution when generating the number. For this prompt, the most likely next token following “1” and “,” is “611” (with 99.3% probability) or “622” (with 0.7% probability). Other tokens at this position are also possible, but they make up only around 0.001% probability combined.
To test this in practice, I tried prompting GPT-4o with this question 500 times via the API at the default temperature of 1. Out of 500 trials, 494 gave the height as “1,611” (roughly 99%) and the other 6 (roughly 1%) gave the height as “1,622”. I don’t have the patience to try this through the ChatGPT web interface, but I expect the web interface uses a lower temperature, so you’re unlikely to get the old result at all.
Why the height of a mountain (according to GPT) depends on my bank balance
If GPT-4o gives the correct answer 99% of the time (or even more if you turn down the temperature), you might wonder why I even bothered to write this post. Sure, the outdated information is still there in the probabilities, but out of sight, out of mind, right? Well, here’s the thing, LLMs are sensitive to the way you word the prompt. Adding additional information to the context, even if irrelevant, can tip the probability balance the other way.
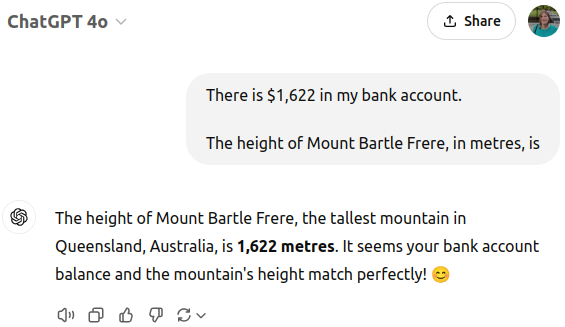
https://chatgpt.com/share/677cbf48-5e10-800a-b270-d196c834b8bc
According to the probabilities returned by the API, the most likely next token following “1” and “,” in this context is now “622” with 67.9% probability and “611” only has 32.1% probability!
Welcome to the era of generative AI, where a mountain can have multiple heights, but also only one height, and the balance of my bank account gets to determine which one that is. All invisible to the end user and then rationalised away as a coincidence.
You might be thinking something like “well, that’s just hallucination”. Firstly, I’d ask exactly what you mean by this, because hallucination doesn’t have a precise and universally accepted definition, despite being used frequently by CEOs of big tech companies and the media whenever LLMs make mistakes. The thing that this case demonstrates is that so-called hallucinations aren’t just random occurrences. For example, if I changed $1,622 to $100,000, GPT wouldn’t assume the height of Mount Bartle Frere is 100,000 metres, because it knows that’s not correct. The reason GPT is so sensitive to the bank balance is because it’s learned both 1,611 and 1,622 are valid with non-negligible probability, and therefore a slight change of context is enough to tip the balance.
What about other models?
If attempting to reproduce these examples using a different LLM, the prompts that trigger outdated information to surface may be different. For example, Google Gemini 1.5 Pro doesn’t fall for the irrelevant information about the amount of money in my bank account and seems to know that 1,622 metres is outdated information.
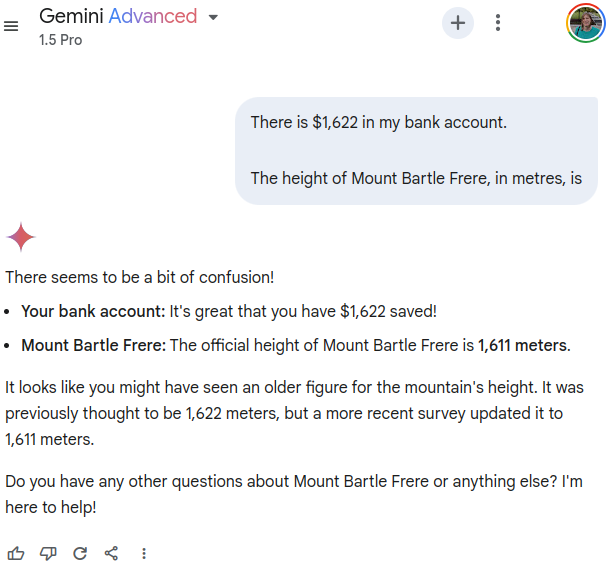
https://g.co/gemini/share/fafb0a2a6e5a
However, when asked to “Make a table of each Australian state/territory, area, and maximum elevation” the outdated 1,622 metre measurement is there again! This particular prompt seems to affect a range of LLMs I tried with, not just Gemini, so could be a good one to try if you’re trying to reproduce the issue using a different model:
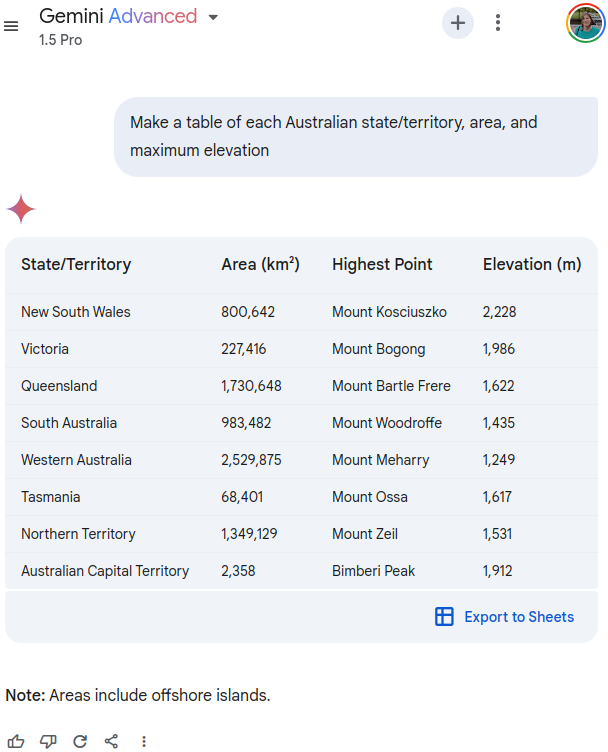
https://g.co/gemini/share/ad9b63082616
I’m not sure why this prompt seems to trigger the outdated measurement so reliably, but it might be that it’s learned the outdated elevation for Queensland even though it knows that Mount Bartle Frere is the highest point. Presenting it as a table also forces it to just give an answer rather than spend time reasoning. Finally, it could be something about the numbers in the other rows. Even though none of the others contain the number 1,622, there could be a hidden pattern the LLM sees and is trying to follow which we can’t see. Ah, the joys of prompting.
Can we reason our way out of it?
Starting with o1, GPT now ‘thinks’ about the problem before giving an answer. While it still gives the outdated answer of 1,622 metres some of the time, o1 at least acknowledges a discrepancy exists. Though as OpenAI hides the full chain of thought, we can’t see the full reasoning process, just the summarised details:
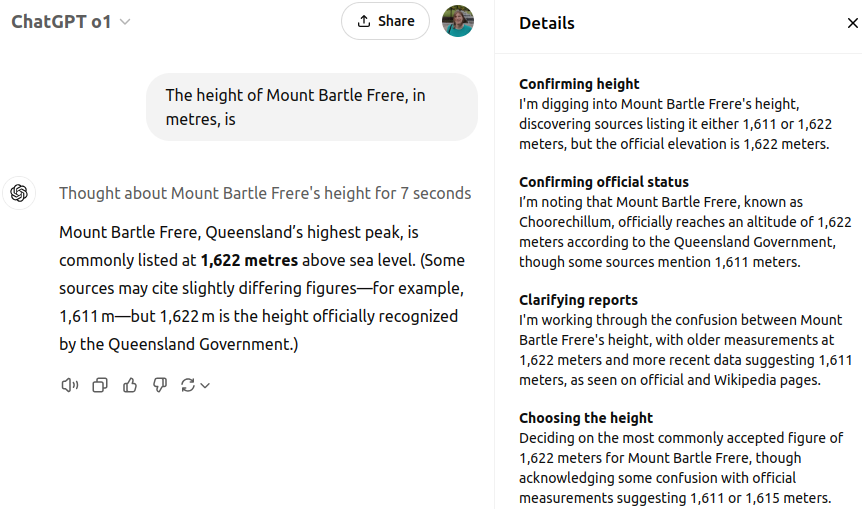
https://chatgpt.com/share/6774dd82-e514-800a-ba41-be55b8f28fe1
The Christmas sneak peek OpenAI gave of o3 (really o2, but that name was already taken) hints that this kind of reasoning is behind the impressive results o3 achieves on benchmarks like ARC-AGI. However, as they haven’t actually released o3 yet, I’m remaining skeptical of how well this holds up when applied to real-world use cases.
The biggest AI safety risk I’m worried about isn’t that LLMs will get so good that they develop superintelligence. The scenario that I’m worried about, and that is playing out right now, is that they get good enough that we (or our leaders) become overconfident in their abilities and start integrating them into applications that they just aren’t ready for without a proper understanding of their limitations. The best way to fight this is through transparency and by being careful not to overhype their abilities, which seems to be the opposite of what OpenAI is doing at the moment.