LLMs are not enough… why chatbots need knowledge representation
Six years ago, I wrote a blog post “Name a fruit that isn’t orange…” pointing out that the best AI and chatbots available at the time got this simple question wrong. Though there was some debate on r/programming about whether this was just “a problem with parsing natural language” or something more fundamental.
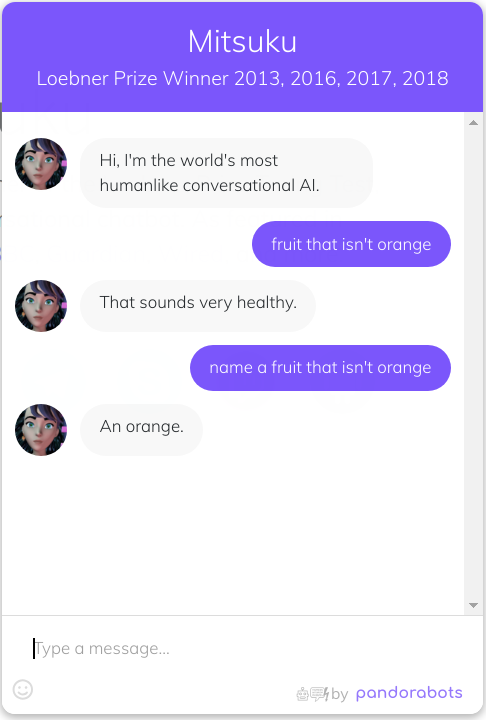
At the time, I thought the solution was the semantic web, an ambitious vision and set of W3C standards intended to formally represent knowledge (including concepts such as negation) on the web.
Since then, we’ve seen the rise of large language models (LLMs) trained on vast quantities of textual data (as well as images in the case of GPT-4 and video + audio in the case of Gemini), giving them knowledge about everything from the colour of fruit to the highest mountain in each state, no semantic web needed! Additionally, since they operate on text, problems parsing the question are no longer a valid excuse for giving an incorrect answer.
Early LLMs still needed to be prompted in a certain way, and struggled with concepts such as isn’t.
BERT Base (110M params):
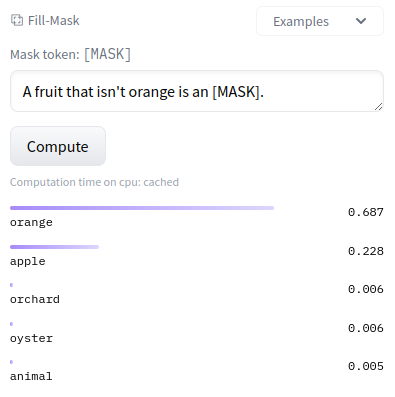
BERT Large (340M params):

Instruction tuned models like ChatGPT allow asking the question directly. ChatGPT is also much larger than its predecessors, which not only allows it to learn more factual knowledge, but also to reason better. Some at Microsoft Research have gone as far as to claim “Sparks of AGI”.
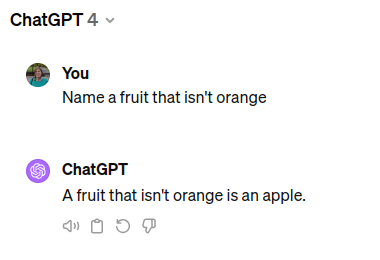
https://chat.openai.com/share/0cb6da69-bba1-42f2-ac65-417b0cfd012b
So, looks like I was wrong. All we needed was a big enough language model, right?
LLMs are not enough
There’s a catch. Rather than explicitly representing the knowledge learned using semantic web standards or any other form of standard, LLMs internalise the knowledge as weights and biases of a neural network used to to predict the next word (or more precisely, next token).
“But does this really matter?” you might ask. Even if we can’t see the knowledge an LLM has learned by inspecting the weights and biases directly, we can extract it through prompting. For example, let’s see what it knows about the state that I live in:

https://chat.openai.com/share/6b8184f6-d0bf-4dc4-baec-af55c8912b3e
Great, it can regurgitate some facts it ‘knows’ about Victoria, but an intelligent chatbot should also be able to use this knowledge to answer questions it’s never seen before. Let’s write a prompt (in a new chat so it can’t cheat) that should return Victoria.

https://chat.openai.com/share/301e8272-869a-4b2f-a3c3-7514108de3d4
Because LLMs generate the response one token at a time, from the moment it guesses “Tasmania” it’s committed to continuing the rest of the answer even when it becomes increasingly apparent this answer is wrong (on a side note, research suggests the internal state of an LLM knows when it’s lying). To its credit, ChatGPT eventually admits there was a mistake, but corrects to “no Australian state strictly meets both conditions” despite there being one that matches the criteria perfectly: Victoria.
Maybe, it’s just a ChatGPT issue? Let’s try Gemini:
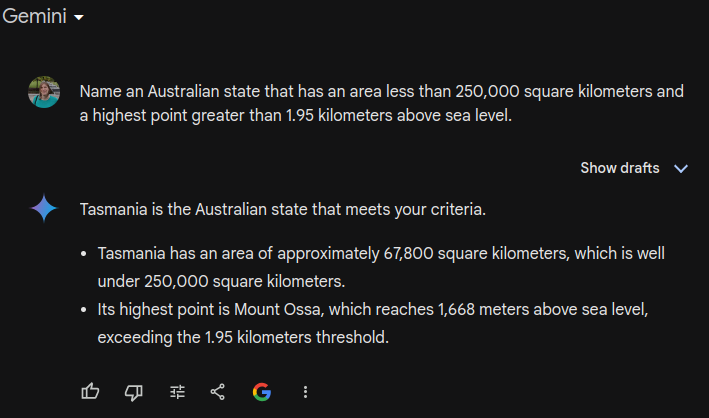
https://g.co/gemini/share/850ffcc074f2
“1,668 meters above sea level, exceeding the 1.95 kilometers threshold.” Wat? Maybe it just doesn’t understand the metric system. Let’s try Gemini Advanced (Ultra), Google’s “most capable AI model”:
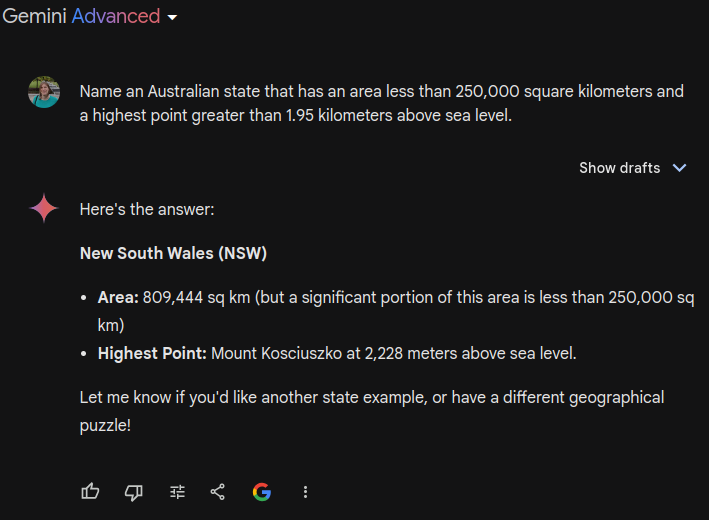
https://g.co/gemini/share/b33726e70bcc
Sigh… At least ChatGPT was able to admit when it was wrong. Gemini is like a politician who makes a mistake but continues to insist they were technically correct.
As you can see, ChatGPT, Gemini (or more generally any other LLM trained in that manner) are unable to reliably search for things that match criteria they haven’t seen before, even if they seem to have access to all the knowledge needed in another context.
Knowledge Representation
The solution? Explicitly state all relevant knowledge first (ChatGPT will even write code to do it)
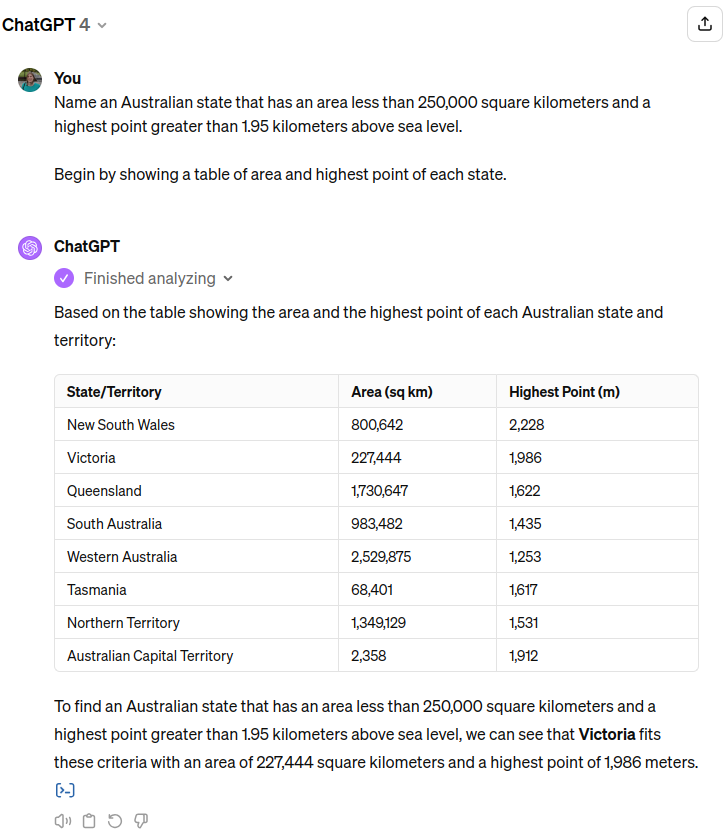
https://chat.openai.com/share/e86660fe-a0db-4f37-8ceb-4692525b53dd
Success! However, this approach is slow and expensive. Every token generated costs both financially due to the expensive GPUs needed to run LLMs as well as environmentally due to the energy those GPUs consume. Every time someone wants to ask a slightly different question (e.g. change the criteria from 1.95 km to 1.96 km), they still need to regenerate the table even if it’s the same information.
In theory, there’s a much better way to answer these kinds of questions:
- Use an LLM to extract knowledge about any topics we think a user might be interested in (food, geography, etc.) and store it in a database, knowledge graph, or some other kind of knowledge representation. This is still slow and expensive, but it only needs to be done once rather than every time someone wants to ask a question.
- When someone asks a question, convert it into a database SQL query (or in the case of a knowledge graph, a graph query). This doesn’t necessarily need a big expensive LLM, a smaller one should do fine.
- Run the user’s query against the database to get the results. There are already efficient algorithms for this, no LLM required.
- Optionally, have an LLM present the results to the user in a nice understandable way.
In the case of a conventional relational database, LLMs can generate the tables, either extracted from documents or based on what they already know (as we can see from the above example). However, the challenge is designing the database schema. Knowledge graphs are a much more flexible way to represent knowledge because they allow storing arbitrary facts.
For answering questions about your own datasets, there’s already a LangChain Neo4j Integration to allow LLMs to query a knowledge graph, which can be coupled with the Diffbot service to extract the knowledge graph. Microsoft’s recent announcement of GraphRAG seems to be heading in a similar direction.
But what about if we want to be able to ask questions about anything? Wikidata is a knowledge graph that can be read and edited by humans and machines. However, I’ve found that while it contains a lot of factual information (e.g. the density of glass) it misses commonsense information (e.g. glass windows make a shattering sound when you break them) which is important for chatbots. One approach might be Symbolic Knowledge Distillation proposed by Allen AI to extract the commonsense information LLMs already know. The problem, however, is that the real world is messy. Can we really expect to reduce nuanced information to facts in a knowledge graph?
Constraining the way we represent knowledge (e.g. a state has an area and a highest point) makes it easier to search and reason about, but may prevent capturing more nuanced/abstract kinds of knowledge. However, if we can get the balance right, this could be the key to a more affordable, reliable and environmentally responsible approach than selling subscriptions to ever larger LLMs.